Step 2: Add Object Detection + Counting
Step 2: Add Object Detection + Counting (aka "teach the model to count, finally")
Right now your captions come from BLIP alone, which is great at vibes but not great at facts.It can describe a scene nicely, but when it comes to counting or being precise... it starts guessing like it's in a multiple-choice exam.
What's the problem?
BLIP is weak at:- counting objects
- being precise ("a fruit" vs "2 apples")
So you might get something like:
"a group of people sitting at a table"
when in reality it's clearly 5 people and 3 pizzas and someone is judging your life choices.
What are we adding?
We introduce YOLOv8 nano for object detection.This model is fast, lightweight, and very good at identifying and counting objects in an image.
Then we combine its output with BLIP.
Now we have:
BLIP = storyteller
YOLO = accountant
Install Additional Dependency
We need the Ultralytics package:pip install ultralyticsAdd it to your requirements.txt so Docker doesn't forget it exists:
ultralytics
Loading YOLOv8
This is surprisingly simple. Almost suspiciously simple.
from ultralytics import YOLO
yolo_model = YOLO("yolov8n.pt")
Yes, that's it. It auto-downloads the model if needed.No drama. No ceremony.
Running Object Detection
We feed the same image into YOLO and extract detected objects.
def detect_objects(image_path):
results = yolo_model(image_path)
detections = results[0].boxes
names = results[0].names
object_counts = {}
for box in detections:
cls_id = int(box.cls[0])
label = names[cls_id]
object_counts[label] = object_counts.get(label, 0) + 1
return object_counts
Now we get something like:
{
"person": 5,
"pizza": 3,
"chair": 6
}
Look at that. Numbers. Actual numbers. Civilization.Merging YOLO with BLIP
Now comes the fun part: combining both outputs into a better caption.
def generate_enhanced_caption(image_path):
caption = generate_caption(image_path)
objects = detect_objects(image_path)
object_summary = ", ".join(
[f"{count} {name}s" for name, count in objects.items()]
)
final_caption = f"{caption}. Detected: {object_summary}."
return final_caption
Example output:"a group of people sitting at a table. Detected: 5 persons, 3 pizzas, 6 chairs."Is it grammatically perfect? Not always.
Is it way more useful? Absolutely.
Update Your API
Swap out the old function with the enhanced one:
@app.post("/caption")
async def caption_image(file: UploadFile = File(...)):
file_path = f"temp_{file.filename}"
with open(file_path, "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
caption = generate_enhanced_caption(file_path)
return {"caption": caption}
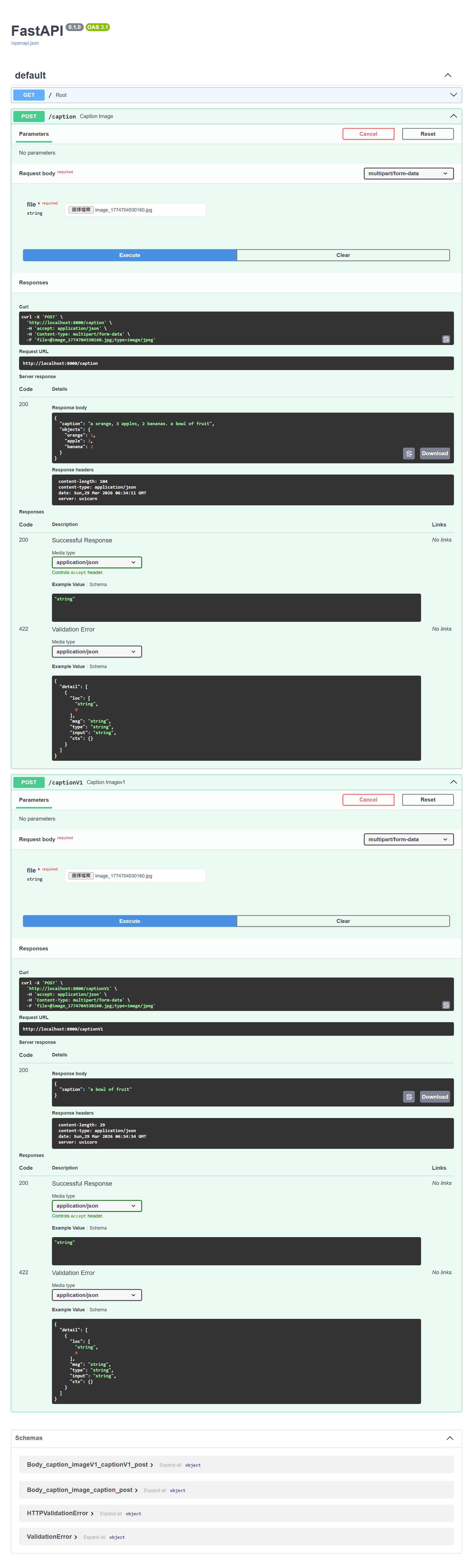
Actual Results
For this photo:
We got the following result, comparing step 1 and step 2:
Performance Considerations
You just added another model, so yes, things get heavier.But YOLOv8 nano is optimized for speed, so it's still quite reasonable.
If needed, you can later:
- run YOLO on GPU
- batch requests
- cache results
But for now, we keep it simple and working.
What You Just Achieved
Technically:- Integrated object detection into your pipeline
- Extracted structured data (object counts)
- Combined multimodal outputs into a richer caption
Emotionally:
- Your model stopped guessing and started counting
- You upgraded from "vibes AI" to "data-driven AI"
Why This Step Matters
This is where your system becomes more than just a demo.You're no longer relying on a single model.
You're orchestrating multiple models to complement each other.
And this is the core idea behind real-world AI systems:
no single model does everything well, but together they look very smart.
Step 2 is done.
Your model can now see, describe, and count.
It's basically becoming a very observant human.
Any comments? Feel free to participate below in the Facebook comment section.
Enjoy the following random pages..
 This website helps C++ programmers improve their programming skills!
This website helps C++ programmers improve their programming skills!
 This website is for Prader Willi Syndrome Association who help Prader Willi Syndrome patients.
This website is for Prader Willi Syndrome Association who help Prader Willi Syndrome patients.
 This program uses Google API to search for documents similar to the given one.
This program uses Google API to search for documents similar to the given one.
 This is a draught puzzle solving program written in C.
This is a draught puzzle solving program written in C.