Learning Rate Schedule With Cosine Annealing
I wrote an app to classify an object using transfer learning, and the model was trained on CIFAR-10 dataset, all by myself.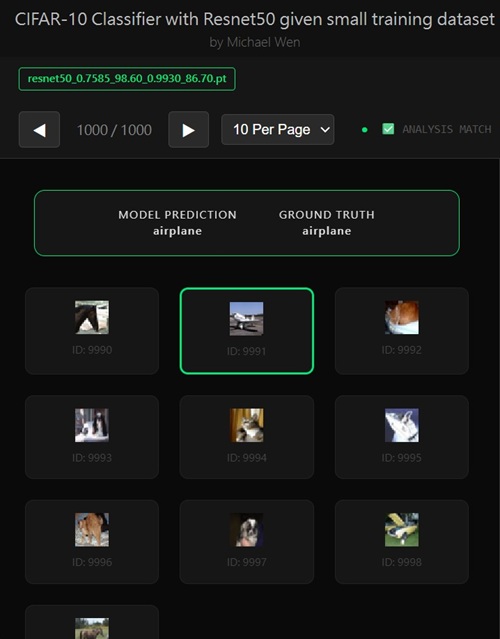
CosineAnnealingLR: A Smooth and Principled Learning Rate Schedule
Why Learning Rate Scheduling Matters
In transfer learning, especially with a pretrained backbone likeResNet-18, the learning rate plays a disproportionate role in
final validation accuracy. Early in training, we want sufficiently large
updates to adapt pretrained features to the new task. Later on, however,
large learning rates become harmful—they cause the optimizer to overshoot
good minima and introduce unnecessary noise into fine-grained weight
adjustments.A learning rate scheduler exists precisely to manage this trade-off. Among many options, CosineAnnealingLR is one of the most effective and theoretically grounded schedules for transfer learning.
How CosineAnnealingLR Works
CosineAnnealingLR gradually decreases the learning rate following a cosine curve rather than a linear or step-wise decay. The learning rate at training stept is defined as:
LR(t) = LR_min + 0.5 × (LR_max − LR_min) × (1 + cos(π × t / T))
Where:
LR_maxis the initial learning rateLR_minis the minimum learning rateTis the total number of epochs (or steps)tis the current epoch
LR_max. As training progresses, the cosine value
smoothly decreases toward −1, causing the learning rate to decay gently and
continuously until it reaches LR_min at the final epoch.
Why Cosine Decay Is Better Than Step Decay
Traditional step schedulers abruptly reduce the learning rate at predefined epochs (e.g., divide by 10 at epoch 30). These sudden drops can disrupt optimization, especially when fine-tuning pretrained models where stability is critical.CosineAnnealingLR avoids this problem entirely:
- No sudden learning rate jumps
- No hand-tuned decay milestones
- Continuous, smooth reduction of update magnitude
What It Does to the Loss Landscape
Early in training, higher learning rates encourage exploration of the loss surface and help the model escape sharp or suboptimal minima inherited from ImageNet pretraining. As the learning rate decays, the optimizer’s trajectory becomes more conservative, allowing it to settle into flatter, more stable minima.Flatter minima are strongly correlated with better generalization. In practice, this means better validation accuracy and less sensitivity to small dataset shifts.
Why CosineAnnealingLR Works Especially Well for ResNet-18
ResNet-18 has relatively limited capacity compared to deeper architectures, which makes optimization stability particularly important. Cosine annealing helps in several ways:– It prevents over-updating early convolutional layers when they are partially unfrozen
– It allows the classifier head to converge quickly, then refine gradually
– It complements regularizers like data augmentation and label smoothing
Because ResNet-18 converges quickly, a smooth decay schedule ensures that later epochs are still productive rather than noisy.
Expected Validation Accuracy Gains
In practical transfer learning setups with ResNet-18 (small to medium-sized datasets), CosineAnnealingLR typically yields:– +0.5% to +1.5% improvement in validation accuracy compared to a constant learning rate
– More stable validation curves with fewer late-epoch regressions
– Faster convergence to peak validation accuracy
While the exact gain depends on dataset size, augmentation strength, and fine-tuning depth, CosineAnnealingLR is rarely neutral—it almost always improves either peak accuracy, stability, or both.
Interaction with Two-Stage Fine-Tuning
Cosine annealing pairs particularly well with two-stage fine-tuning:Stage 1: Higher effective learning rates help quickly adapt the classifier and upper layers.
Stage 2: As deeper layers are unfrozen, the naturally lower learning rate prevents catastrophic forgetting of pretrained features.
This makes CosineAnnealingLR an excellent default choice when progressively unfreezing ResNet blocks.
Key Takeaway
CosineAnnealingLR is more than a cosmetic learning rate decay—it encodes a strong optimization prior: explore first, refine later. For transfer learning with ResNet-18, it provides smoother optimization, better-calibrated weights, and consistently higher validation accuracy with minimal tuning effort.In short, it is a low-risk, high-reward scheduler that should be part of any serious transfer learning baseline.
Any comments? Feel free to participate below in the Facebook comment section.