Importance Of Input Data Normalization
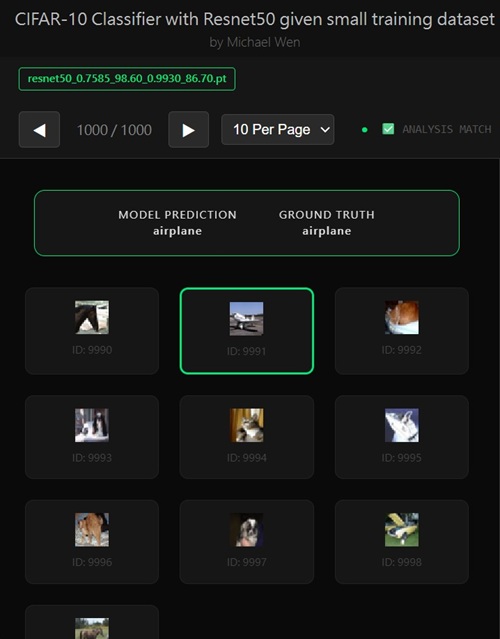
Note: I wrote an app to classify an object using transfer learning, and the model was trained on CIFAR-10 dataset, all by myself.Here's the app:
Input Normalization and Its Role in Transfer Learning
Why Normalization Is Always Applied
When sampling training and test data from theCIFAR-10 dataset,
we consistently apply input normalization using the following statistics:
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
These values are not arbitrary. They are the channel-wise mean and standard deviation used during the pretraining of
ResNet(weights=IMAGENET1K_V1) on ImageNet.
As a result, the pretrained model implicitly assumes that all input images are normalized
in exactly this manner.
What Happens If You Normalize Incorrectly
If inputs are not normalized correctly, the distribution of activations entering the network will deviate significantly from what the pretrained weights expect. This has several negative consequences:– Feature magnitudes become mis-scaled, causing early convolutional filters to respond incorrectly
– Batch normalization layers receive shifted activation statistics, reducing their effectiveness
– Gradient flow becomes unstable, leading to slow convergence or complete training collapse
In practice, using an incorrect mean or standard deviation is one of the most common silent bugs in transfer learning. The training process may appear to run normally, but validation performance degrades sharply with no obvious error messages.
Normalization as a Contract with the Pretrained Model
Input normalization can be thought of as a contract between the data pipeline and the pretrained model. By matching the original training distribution, we ensure that:– Low-level features such as edges and textures activate as intended
– Higher-level representations remain semantically meaningful
– Fine-tuning focuses on task adaptation rather than distribution correction
Example: PyTorch Normalization Pipeline
Below is a typical normalization setup used in our experiments:
from torchvision import transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
Adapting Normalization for Other Foundation Models
It is important to note that normalization statistics are model-dependent. If a different foundation model is used—especially one trained on a different dataset or with a different preprocessing pipeline—the mean and standard deviation may need to be adjusted accordingly.For example:
– Models pretrained on datasets other than ImageNet may use different normalization statistics
– Some architectures expect inputs scaled to
[−1, 1] rather than standardized per channel– Self-supervised or contrastive models may apply custom normalization during pretraining
Key Takeaway
Correct input normalization is not a minor implementation detail—it is a prerequisite for effective transfer learning. Ensuring that the input distribution matches the assumptions of the pretrained weights is essential for stable optimization and strong downstream performance.Any comments? Feel free to participate below in the Facebook comment section.